基本概念
正则表达式是一种文本模式,包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为“元字符”)。模式描述在搜索文本时要匹配的一个或多个字符串。
正则表达式是一种查找以及字符串替换操作。正则表达式在文本编辑器中广泛使用,比如正则表达式被用于:
- 检查文本中是否含有指定的特征词
- 找出文中匹配特征词的位置
- 从文本中提取信息,比如:字符串的子串
- 修改文本
字符类匹配
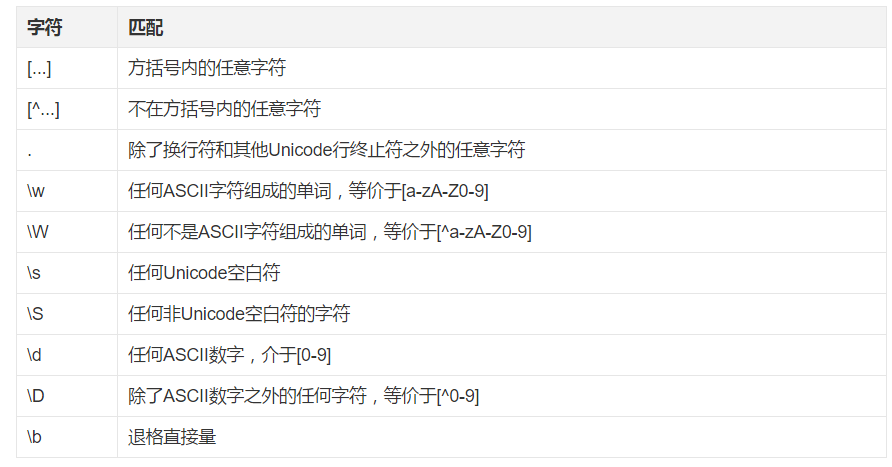
重复字符匹配
正则表达式修饰符
字符含义
i 执行不区分大小写的匹配
g 执行一个全局匹配,即找到所有匹配而非一次匹配
m 多行匹配模式,^匹配一行的开头和字符串开头,$匹配行的结束和字符串的结尾
说明:正则表达式通常用于两种任务:1.验证,2.搜索/替换。用于验证时,通常需要在前后分别加上^和$,以匹配整个待验证字符串;搜索/替换时是否加上此限定则根据搜索的要求而定,此外,也有可能要在前后加上\b而不是^和$。此表所列的常用正则表达式,除个别外均未在前后加上任何限定,请根据需要,自行处理。
RegExp的方法
RegExp 对象有 3 个方法:test()、exec() 以及 compile()。
- test():检索字符串中的指定值。返回值是布尔值。
- exec():返回一个数组,数组中的第一个条目是第一个匹配,其他的是反向引用
- compile() 既可以改变检索模式,也可以添加或删除第二个参数。
建立正则表达式
构造正则表达式的方法和创建数学表达式的方法一样。也就是用多种元字符与操作符较小的表达式结合在一起来创建更大的表达式。
可以通过在一对分隔符之间放入表达式模式的各种组件来构造一个正则表达式。
对 js 而言,分隔符为一对正斜杠 (/) 字符。例如:
/expression/
看个例子
1 | //匹配帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线 |
正则表达式的组件可以是单个的字符、字符集合、字符范围、字符间的选择或者所有这些组件的任意组合。
match 方法
1 | /*使用 match 方法获取获取匹配数组*/ |
search方法
1 | /*使用 search 来查找匹配数据*/ |
replace方法
1 | /*使用 replace 替换匹配到的数据*/ |
split方法
1 | /*使用 split 拆分成字符串数组*/ |
常用的正则表达式
匹配中文字符的正则表达式: [\u4e00-\u9fa5]
评注:匹配中文还真是个头疼的事,有了这个表达式就好办了
匹配双字节字符(包括汉字在内):[^\x00-\xff]
评注:可以用来计算字符串的长度(一个双字节字符长度计2,ASCII字符计1)
匹配空白行的正则表达式:\n\s*\r
评注:可以用来删除空白行
匹配HTML标记的正则表达式:<(\S?)[^>]>.?</\1>|<.? />
评注:网上流传的版本太糟糕,上面这个也仅仅能匹配部分,对于复杂的嵌套标记依旧无能为力
匹配首尾空白字符的正则表达式:^\s|\s$
评注:可以用来删除行首行尾的空白字符(包括空格、制表符、换页符等等),非常有用的表达式
匹配Email地址的正则表达式:\w+([-+.]\w+)@\w+([-.]\w+).\w+([-.]\w+)*
评注:表单验证时很实用
匹配网址URL的正则表达式:[a-zA-z]+://[^\s]*
评注:网上流传的版本功能很有限,上面这个基本可以满足需求
匹配帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$
评注:表单验证时很实用
匹配国内电话号码:\d{3}-\d{8}|\d{4}-\d{7}
评注:匹配形式如 0511-4405222 或 021-87888822
匹配腾讯QQ号:[1-9][0-9]{4,}
评注:腾讯QQ号从10000开始
匹配中国邮政编码:[1-9]\d{5}(?!\d)
评注:中国邮政编码为6位数字
匹配身份证:\d{15}|\d{18}
评注:中国的身份证为15位或18位
匹配ip地址:\d+.\d+.\d+.\d+
评注:提取ip地址时有用